title: 什么是线程束执行状态?
运行内核的线程束状态可通过多个非互斥的形容词来描述:活跃的、停滞的、符合条件的和被选中的。
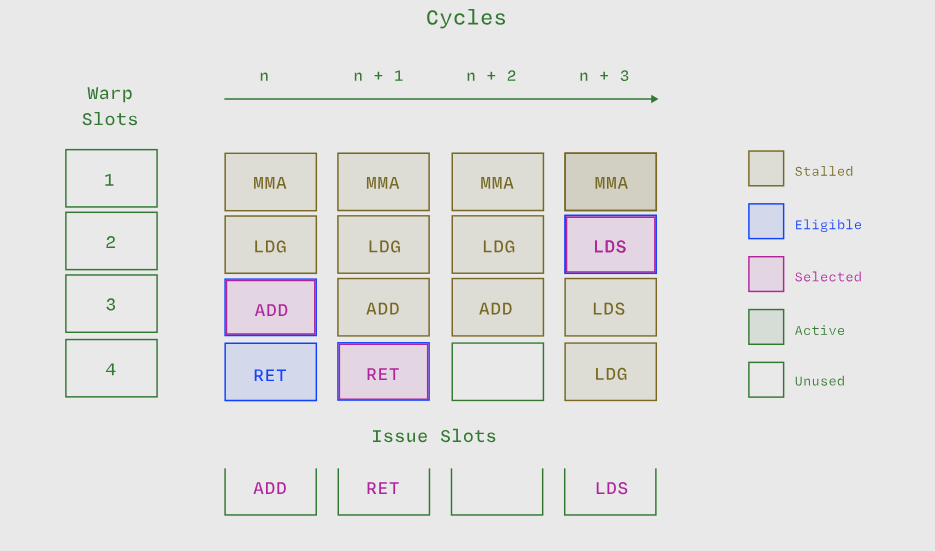
线程束执行状态通过颜色表示。图表灵感来源于 GTC 2025 的 CUDA Techniques to Maximize Compute and Instruction Throughput 演讲。
从线程开始执行,到线程束中的所有线程都从内核退出为止,该线程束被认为是活跃的。活跃的线程束构成了一个资源池,线程束调度器每个周期从中选择候选者来发射指令(即放入某个发射槽中)。
每个流式多处理器 (SM) 上活跃线程束的最大数量因架构而异,并在 NVIDIA 文档中针对计算能力列出。例如,在具有计算能力 9.0 的 H100 SXM GPU 上,每个 SM 最多可以有 64 个活跃线程束(2048 个线程)。请注意,活跃的线程束不一定正在执行指令。在上图中,除了一个槽位+周期外,其余所有槽位+周期都有活跃的线程束——这表明了高占用率。
一个符合条件的线程束是指一个活跃的线程束,它已准备好发射其下一条指令。要使一个线程束符合条件,必须满足以下所有条件:
- 下一条指令已被获取,
- 所需的执行单元可用,
- 所有指令依赖关系已解决,并且
- 没有同步屏障阻塞执行。
符合条件的线程束代表了线程束调度器进行指令发射的即时候选者。在上图中,除了周期 n + 2 之外的所有周期都出现了符合条件的线程束。在许多周期内没有符合条件的线程束可能对性能不利,特别是当您主要使用像 CUDA 核心 这样的低延迟算术单元时。
一个停滞的线程束是指一个活跃的线程束,由于未解决的依赖关系或资源冲突而无法发射其下一条指令。线程束因各种原因而停滞,包括:
- 执行依赖,即它们必须等待先前算术指令的结果,
- 内存依赖,即它们必须等待先前内存操作的结果,
- 流水线冲突,即执行资源当前被占用。
当线程束因访问共享内存或因执行长时间运行的算术指令而停滞时,我们称其停滞在"短计分板"上。当线程束因访问 GPU RAM 而停滞时,我们称其停滞在"长计分板"上。这些是线程束调度器内部的硬件单元。计分板是一种在动态指令调度中用于跟踪依赖关系的技术,其历史可以追溯到"第一台超级计算机"——Control Data Corporation 6600,其中一台在 1966 年推翻了欧拉幂和猜想。与 CPU 不同,计分板不用于线程内部的乱序执行(指令级并行),而只用于跨线程的执行(线程级并行);参见此 NVIDIA 专利。
在上图中,每个周期的多个槽位中都出现了停滞的线程束。停滞的线程束本身并不一定是坏事——大量并发停滞的线程束集合可能是隐藏延迟所必需的,这些延迟来自长时间运行的指令,如内存加载或像 HMMA 这样的张量核心指令,这些指令可能运行数十个周期。
一个被选中的线程束是指一个符合条件的线程束,它在当前周期被线程束调度器选中以接收一条指令。每个周期,线程束调度器会查看其符合条件的线程束资源池,如果存在任何符合条件的线程束,则选择一个并向其发射一条指令。在每个有符合条件的线程束的周期中,都有一个被选中的线程束。在活跃周期中,某个线程束被选中并发射指令的比例就是发射效率。