title: 什么是 Tensor Core?
Tensor Core 是一种 GPU 核心 (core),能够通过单条指令对整个矩阵进行操作。
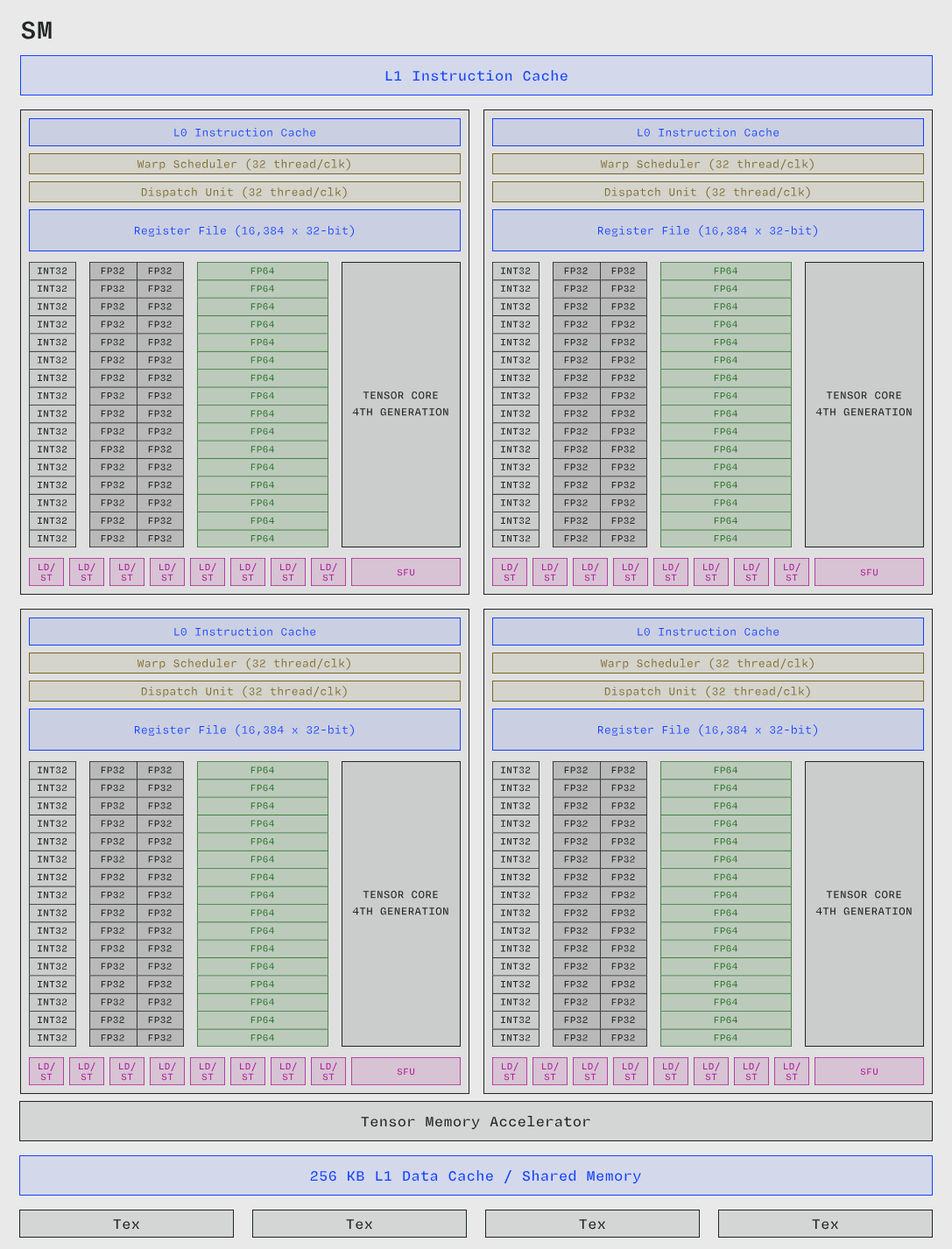
H100 SM 的内部架构。注意 Tensor Core 数量较少但尺寸更大。改编自 NVIDIA 的 H100 白皮书。
单条指令能操作更多数据可显著降低功耗需求,从而释放更高性能(参见 NVIDIA 首席科学家 Bill Dally 的 这个演讲)。自 Volta 架构的流式多处理器 (Streaming Multiprocessor, SM) 世代引入以来,Tensor Core 已成为在 NVIDIA GPU 上实现最高算术吞吐量 (arithmetic throughput) 的唯一途径 —— 其每秒浮点运算能力是 CUDA 核心 (CUDA Core) 的 100 倍。
例如,HMMA16.16816.F32 SASS 指令会计算 D = AB + C(其中矩阵 C 通常与 D 是同一物理矩阵)。MMA 代表"矩阵乘加 (Matrix Multiply and Accumulate)"。HMMA16 表示输入为半精度(16 位),F32 表示输出累加到 32 位(即单精度)浮点数中。
中间的 16816 并非一个大于 16,000 的数字,而是由 16、8 和 16 三个数字组成的矩阵维度。NVIDIA 通常将这些维度命名为 m、n 和 k,例如在 PTX 指令中。矩阵 A 和 B 的外部维度(即 m 和 n)在前,用于累加的共享内部维度 k 在后。通过乘法计算可知,HMMA16.16816.32 指令执行了 16 × 8 × 16 = 2,048 次乘加 (MAC) 运算。
需要注意的是,单个线程 (thread) 中的单条指令并不会产生完整的矩阵乘法结果。实际上,一个线程束 (warp) 中的 32 个线程通过协同执行该指令来共同产生结果。得益于线程束调度器 (warp scheduler),大部分指令解码的功耗开销由整个线程束 (warp) 分担。但即使分摊到这 32 个线程上,每条指令仍需执行 64 = 2,048 ÷ 32 次 MAC 运算。
因此,可以将 Tensor Core 及类似硬件(如 Google TPU 中的脉动阵列)视为一种复杂指令集计算机 (complex instruction set computer, CISC) 硬件。关于这一视角在 TPU 上的应用,可参阅计算机架构师 David Patterson 的 这个演讲,他也是 CISC 和 RISC 术语的提出者。
编译器可能会生成该汇编级指令来实现 PTX 层级的矩阵乘加指令,例如 wmma(文档参见 此处)。这些指令同样计算 D = AB + C,但通常会被编译成多个针对较小矩阵操作的 SASS Tensor Core 指令。
来自 PTX 指令集架构的这些指令,在高级 CUDA C++ 编程语言中以内部函数形式暴露。
逆向来看,在 CUDA C++ 中编写两个 16×16 矩阵乘法 C = A @ B 的代码行,如:
wmma::mma_sync(c, a, b, c);
其中 c 初始化为全零,首次出现时也作为输出,可能会被 nvcc 编译为 PTX 中间表示:
wmma.mma.sync.aligned.col.row.m16n16k16.f32.f32 {%f2, %f3, %f4, %f5, %f6, %f7, %f8, %f9}, {%r2, %r3, %r4, %r5, %r6, %r7, %r8, %r9}, {%r10, %r11, %r12, %r13, %r14, %r15, %r16, %r17}, {%f1, %f1, %f1, %f1, %f1, %f1, %f1, %f1};
然后最终由 ptxas 编译为 SASS:
HMMA.1688.F32 R20, R12, R11, RZ // 1
HMMA.1688.F32 R24, R12, R17, RZ // 2
HMMA.1688.F32 R20, R14, R16, R20 // 3
HMMA.1688.F32 R24, R14, R18, R24 // 4
每条 HMMA 指令的操作数可按 D = A @ B + C 的顺序读取。例如,指令 3 使用寄存器 (register) 20 作为输出 D,寄存器 14 和 16 分别作为输入 A 和 B,并复用寄存器 20 作为输入 C,实现了 C += A @ B 计算。
该程序将完整的 16×16 方阵乘法划分为四条独立指令,每条指令本身都是 16×8 矩阵与 8×8 矩阵的乘法。类似地,运行大规模矩阵乘法的程序必须将其工作分解为较小的矩阵乘法,就像我们正在剖析的 mma_sync 调用所执行的 16×16 方阵乘法。下文将逐步解析该程序。
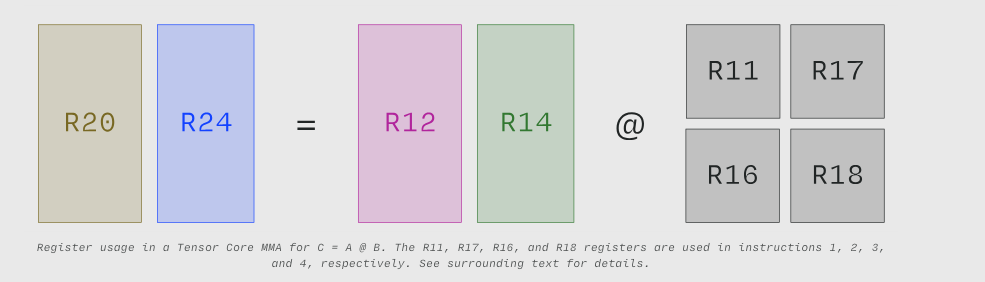
Tensor Core MMA 在 C = A @ B 中的寄存器使用情况。R11、R17、R16 和 R18 寄存器分别用于指令 1、2、3 和 4。详见正文说明。
前两条指令计算输入 a(来自 R12)的前八列与输入 b(来自 R11 和 R17)的前八行的矩阵乘法,生成存储在 R20 和 R24 中的 16×16 矩阵。这是一种"外积":高瘦矩阵与矮宽矩阵相乘。(RZ 是一个特殊用途的"寄存器",其值为 Zero)。
后两条指令为 a 的后八列和 b 的后八行计算类似的"外积",并与前两条指令的输出累加,最终得到 c 的值。
换句话说:在 B 的八行八列块和 A 的整列范围内,Tensor Core 内部会针对该指令并发执行大量乘加运算来实现矩阵乘法。每条指令处理给定 B 行列块对应的 A 的所有 m 行。它们共同完成完整的矩阵乘法。
如需深入探索,可在 Godbolt 上查看此编译器输出。注意这远非使用 Tensor Core 的利用率最大化矩阵乘法!相关实现可参阅 Pranjal Shandkar 的工作日志。
为 Hopper 和 Blackwell Tensor Core 编程以实现最高性能无法仅用纯 CUDA C++ 完成,而需要同时使用计算和内存操作的 PTX 内部函数。通常建议直接使用内核库中的现有内核,如 cuBLAS (CUDA 基础线性代数子程序),或更高级的内核编程接口如 CUTLASS (CUDA 线性代数子程序模板)。关于 CUTLASS 的入门,可参阅 Colfax Research 的博客系列。
Tensor Core 比 CUDA 核心 (CUDA Core) 大得多但数量少得多。H100 SXM5 每个 SM 仅有四个 Tensor Core(即每个线程束调度器 (Warp Scheduler) 一个),但拥有数百个 CUDA 核心 (CUDA Core)。Tensor Core 是 Tensor Memory 的主要生产者和消费者。
Tensor Core 首次出现在 V100 GPU 中,这标志着 NVIDIA GPU 对大型神经网络工作负载适用性的重大提升。更多信息参见 NVIDIA 介绍 V100 的白皮书。
Tensor Core 的内部结构未知,且可能因 SM 架构不同而异。通常假设其为类似 TPU 的脉动阵列,但微基准测试文献中尚未达成共识。