title: 什么是流式多处理器? abbreviation: SM
当我们对 GPU 进行编程时,我们会生成指令序列供其流式多处理器 (Streaming Multiprocessor) 执行。
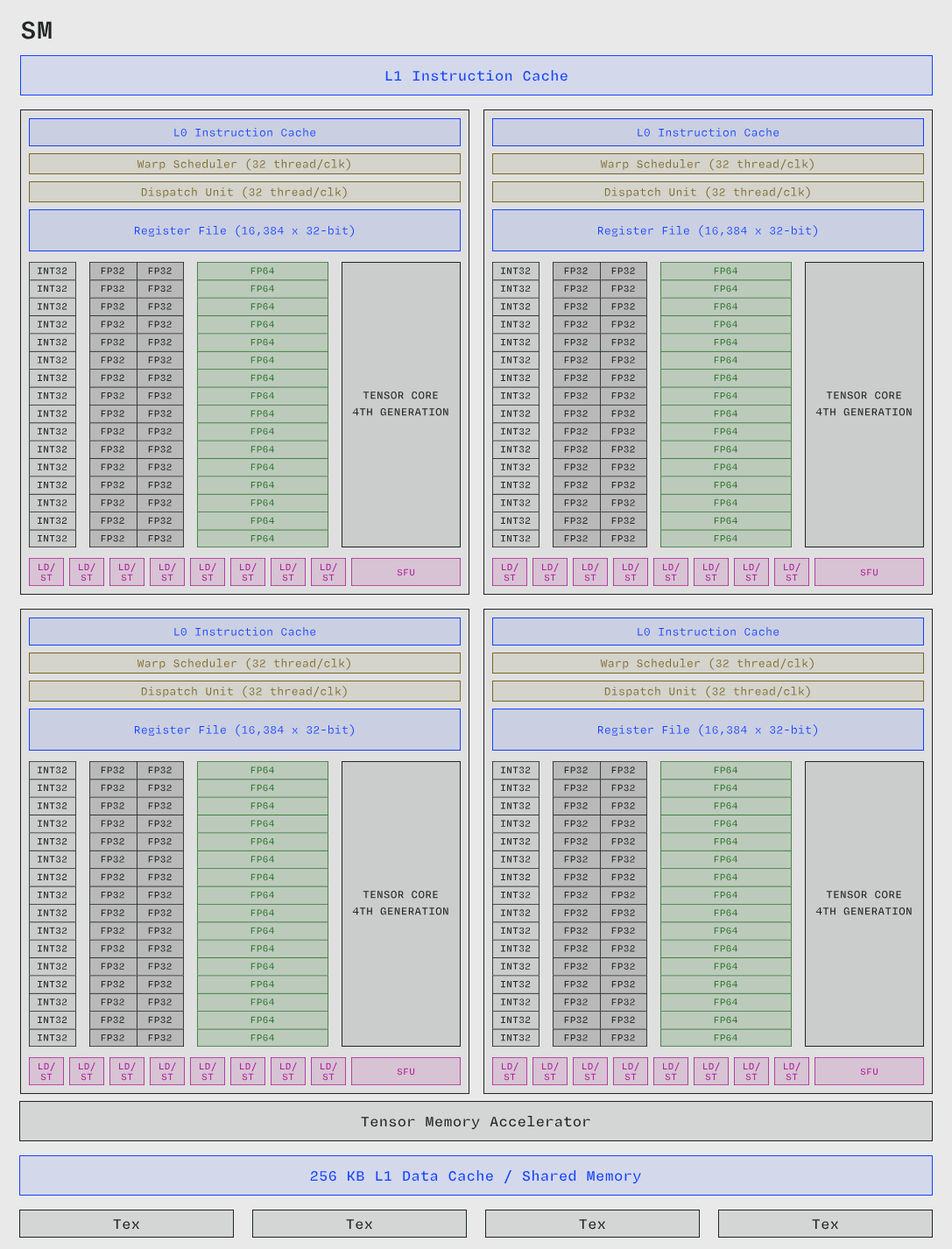
H100 GPU 流式多处理器内部架构示意图。GPU 核心显示为绿色,其他计算单元为栗色,调度单元为橙色,内存为蓝色。修改自 NVIDIA 的 H100 白皮书。
NVIDIA GPU 的流式多处理器 (SM) 大致类似于 CPU 的核心。也就是说,SM 既执行计算,又在寄存器中存储可用于计算的状态,并配有相关的缓存。与 CPU 核心相比,GPU SM 是简单、性能较弱的处理器。SM 中的执行在指令内部是流水线化的(就像自 1990 年代以来的几乎所有 CPU 一样),但没有推测执行或指令指针预测(这与所有当代高性能 CPU 不同)。
然而,GPU SM 可以并行执行更多的线程。
作为对比:一颗 AMD EPYC 9965 CPU 最大功耗为 500 W,拥有 192 个核心,每个核心最多可以同时为两个线程执行指令,总共可并行执行 384 个线程,每个线程的运行功耗约为 1.25 W。
一颗 H100 SXM GPU 最大功耗为 700 W,拥有 132 个 SM,每个 SM 有四个线程束调度器 (Warp Scheduler),每个调度器每个时钟周期可以向 32 个线程(也称为一个线程束 (Warp))并行发出指令,总共超过 16,000 个并行线程在运行,每个线程的功耗约为 5 cW。请注意,这是真正的并行:16,000 个线程中的每一个都可以在每个时钟周期取得进展。
GPU SM 还支持大量并发线程——这些执行线程的指令是交错执行的。
H100 上的单个 SM 可以并发执行多达 2048 个线程,这些线程分布在 64 个线程组中,每组 32 个线程。拥有 132 个 SM,总共超过 250,000 个并发线程。
CPU 也可以并发运行许多线程。但是线程束 (Warp) 之间的切换发生在单个时钟周期内(比 CPU 上的上下文切换快 1000 多倍),这同样得益于 SM 的线程束调度器 (Warp Scheduler)。可用线程束 (Warp) 的数量和线程束切换 (Warp Switch) 的速度有助于隐藏延迟 (Latency Hiding),这些延迟是由内存读取、线程同步或其他昂贵的指令引起的,从而确保由 CUDA 核心 (CUDA Core) 和 张量核心 (Tensor Core) 提供的算术带宽 (Arithmetic Bandwidth) 得到充分利用。
这种延迟隐藏 (Latency Hiding) 是 GPU 优势的秘诀。CPU 试图通过维护大型的、硬件管理的缓存和复杂的指令预测来对最终用户和程序员隐藏延迟。这些额外的硬件限制了 CPU 可以分配给计算的芯片面积比例、功耗和热预算。

与 CPU 相比,GPU 将其更多的面积用于计算(绿色),而更少的面积用于控制和缓存(橙色和蓝色)。修改自 Fabien Sanglard 博客 中的图表,该图表本身可能修改自 CUDA C 编程指南 中的图表。
对于像神经网络推理或顺序数据库扫描这样的程序或函数,程序员相对容易表达缓存的行为——例如,存储每个输入矩阵的一块数据,并将其保留在缓存中足够长的时间以计算相关的输出——其结果是显著更高的吞吐量。