title: 什么是占用率?
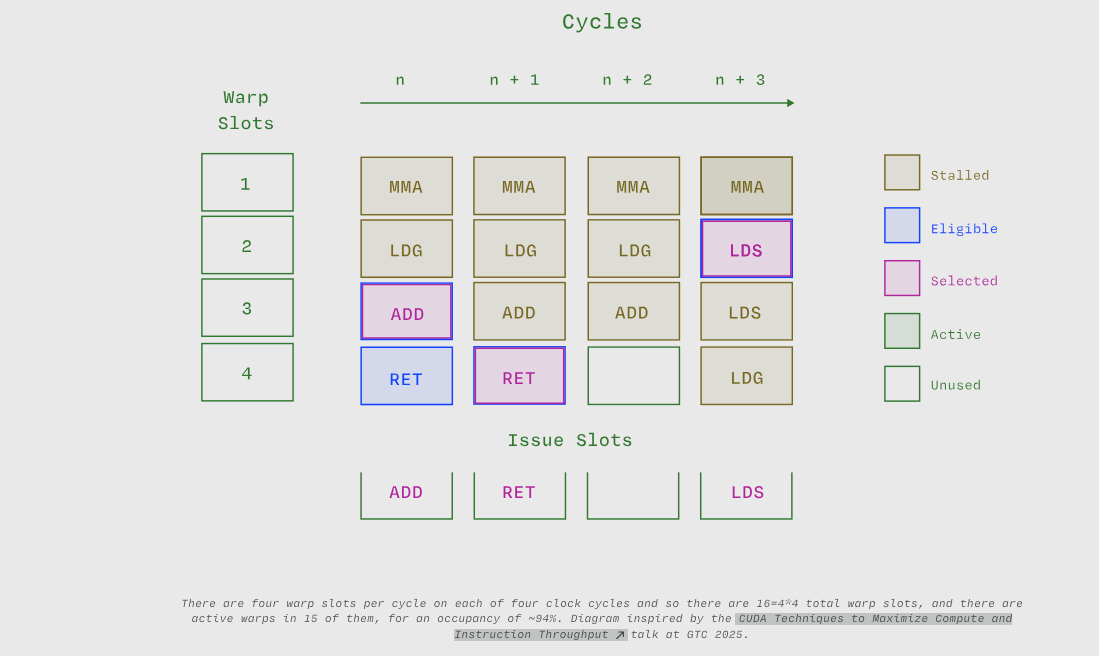
四个时钟周期中每个周期有四个线程束槽位,因此共有16=4*4个线程束槽位,其中15个槽位中有活动线程束,占用率约为94%。图表灵感来自GTC 2025的CUDA Techniques to Maximize Compute and Instruction Throughput演讲。
占用率测量有两种类型:
作为CUDA编程模型的一部分,线程块中的所有线程都被调度到同一个流式多处理器 (SM)上。每个SM都有资源(如共享内存中的空间),这些资源必须在线程块之间进行分配,因此限制了可以在SM上调度的线程块数量。
让我们来看一个例子。考虑NVIDIA H100 GPU,它具有以下规格:
最大线程束/SM:64
最大块/SM:32
(32位)寄存器:65536
共享内存:228 KB
对于一个使用每线程块32个线程、每线程8个寄存器和每线程块12 KB共享内存的内核,我们最终受到共享内存的限制:
64 > 1 = 线程束/块 = 32线程/块 ÷ 32线程/线程束
32 < 256 = 块/寄存器文件 = 65,536寄存器/寄存器文件 ÷ (32线程/块 × 8寄存器/线程)
32 = 块/SM
19 = 块/共享内存 = 228 KB/共享内存 ÷ 12 KB/块
尽管我们的寄存器文件足够大,可以同时支持256个线程块,但我们的共享内存不够,因此我们每个SM只能运行19个线程块,对应19个线程束。这是常见情况,即存储在寄存器中的程序中间结果的大小远小于需要保留在共享内存中的程序工作集元素的大小。
当没有足够的合格线程束来隐藏指令延迟时,低占用率会损害性能,这表现为低指令发射效率和利用率不足的流水线。然而,一旦占用率足以进行延迟隐藏,进一步增加占用率实际上可能会降低性能。更高的占用率会减少每个线程的资源,可能导致内核在寄存器上出现瓶颈或降低现代GPU架构设计用来利用的算术强度。
更一般地说,占用率衡量的是GPU同时处理其最大并行任务的比例,这在大多数内核中本身并不是优化的目标。相反,如果我们处于计算瓶颈,我们希望最大化计算资源的利用率;如果我们处于内存瓶颈,我们希望最大化内存资源的利用率。
特别是,在Hopper和 Blackwell架构GPU上的高性能GEMM内核通常以个位数的占用率百分比运行,因为它们不需要很多线程束来完全饱和张量核心。