title: 什么是内存受限?
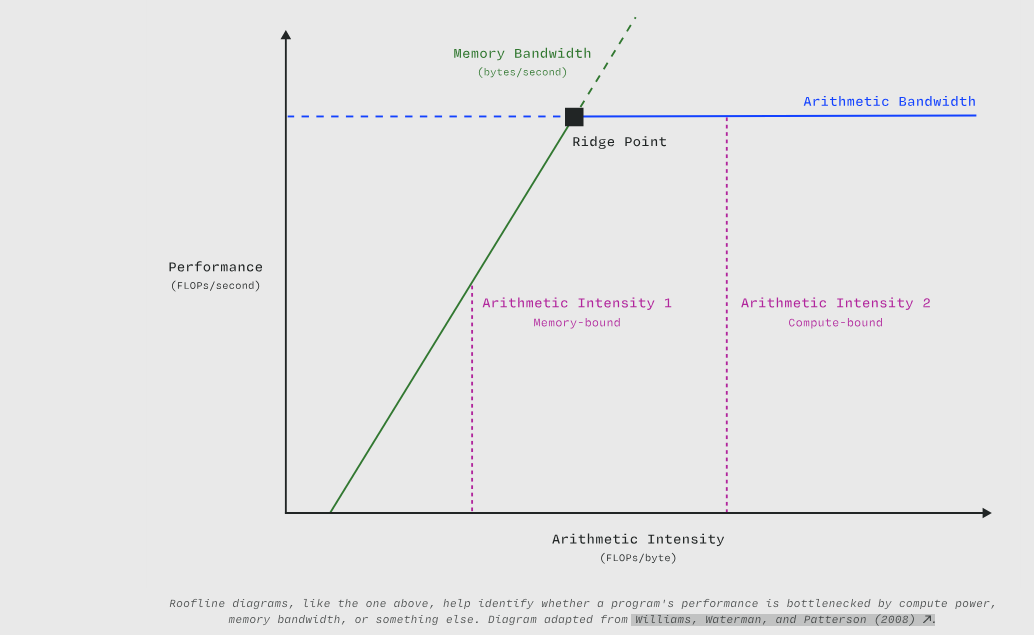
屋顶线图(如上图所示)有助于识别程序性能的瓶颈是计算能力、内存带宽还是其他因素。图表改编自 Williams, Waterman, and Patterson (2008)。
具体来说,它们受限于 GPU 显存与流式多处理器 (Streaming Multiprocessor)的本地缓存之间的带宽,因为 GPU 性能关注的问题通常具有远大于内存层次结构中任何更高级别的工作集大小。
相对于其屋顶线模型的脊点,内存受限的内核具有较低的算术强度(每移动一个字节的操作数更少)。
从技术上讲,内存受限性仅针对单个内核定义,作为屋顶线模型的一部分,但稍加扩展,它可以推广到涵盖构成典型工作负载的多个内核。
当代大语言模型推理工作负载在解码/输出生成阶段通常是内存受限的,此时权重必须在每次前向传播中加载一次。每个输出令牌都会发生一次,除非使用多令牌预测或推测解码,这使得计算内存受限的 Transformer 大语言模型推理中令牌之间的最小延迟(令牌间延迟或每个输出令牌的时间)变得容易。
假设模型有 5000 亿个参数,以 16 位精度存储,总计 1 TB。如果我们在单个 GPU 上运行推理,其内存带宽为 10 TB/s,我们可以每 100 毫秒加载一次权重,这就为我们的令牌间延迟设定了一个下限。通过将多个输入批量处理在一起,我们可以线性增加每个加载参数所执行的浮点操作数(算术强度),原则上直到达到计算受限点,而不会产生任何额外的延迟,这意味着吞吐量随批量大小线性提高。
有关 LLM 推理的更多信息,请参阅我们的 LLM 工程师指南。