title: 什么是 CUDA 内核?
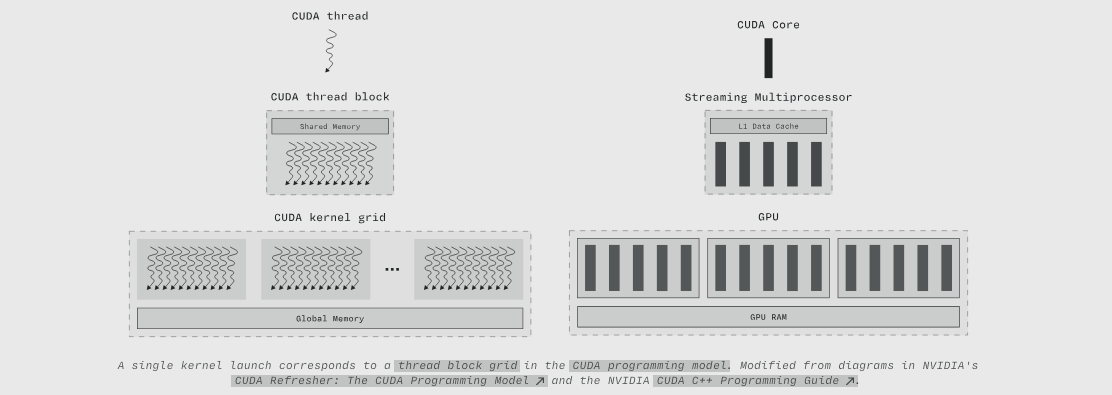
单个内核启动对应于 CUDA 编程模型 中的 线程块网格。改编自 NVIDIA 的 CUDA Refresher: The CUDA Programming Model 和 NVIDIA CUDA C++ Programming Guide 中的图表。
内核是程序员通常编写和组合的 CUDA 代码单元,类似于面向 CPU 的语言中的过程或函数。
与过程不同,内核被调用("启动")一次并返回一次,但会被执行多次,每次由一个 线程 执行。这些执行通常是并发的(它们的执行顺序是不确定的)和并行的(它们在不同的执行单元上同时发生)。
执行内核的所有线程的集合被组织为内核网格——也称为 线程块网格,这是 CUDA 编程模型 的 线程层次结构 的最高级别。内核网格在多个 流式多处理器 (SM) 上执行,因此在整个 GPU 的规模上运行。对应的 内存层次结构 级别是 全局内存。
在 CUDA C++ 中,内核在被主机调用时被传递指向设备上 全局内存 的指针,并且不返回任何内容——它们只是改变内存。
为了展示 CUDA 内核编程的风格,让我们来看两个 CUDA 内核"hello world"的实现:两个方阵 A 和 B 的矩阵乘法。这两个实现的不同之处在于它们如何将教科书中的矩阵乘法算法映射到 线程层次结构 和 内存层次结构 上。
在最简单的实现中,灵感来自 Programming Massively Parallel Processors(第 4 版,图 3.11)中的第一个矩阵乘法内核,每个 线程 完成计算输出矩阵一个元素的所有工作——依次将 A 的特定 row 行和 B 的特定 col 列的元素加载到 寄存器 中,将配对元素相乘,对结果求和,并将总和放回 全局内存。
__global__ void mm(float* A, float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
在这个内核中,每个 线程 每次从 全局内存 读取时执行一次浮点运算 (FLOP):一次乘法和一次加法;从 A 加载一次和从 B 加载一次。这样你永远无法 充分利用整个 GPU,因为 CUDA 核心 以 FLOPs/s 为单位的 算术带宽 远高于 GPU 内存 和 SM 之间的 内存带宽。
我们可以通过更仔细地将该算法中的工作映射到 线程层次结构 和 内存层次结构 上来增加 FLOPs 与内存操作的比例。在下面的"分块"矩阵乘法内核中,灵感来自 Programming Massively Parallel Processors 第 4 版图 5.9,我们将 A 和 B 的子矩阵的加载以及 C 的子矩阵的计算分别映射到 共享内存 和 线程块 上。
#define TILE_WIDTH 16
__global__ void mm(float* A, float* B, float* C, int N) {
// 在共享内存中声明变量
__shared__ float As[TILE_WIDTH][TILE_WIDTH];
__shared__ float Bs[TILE_WIDTH][TILE_WIDTH];
int row = blockIdx.y * TILE_WIDTH + threadIdx.y;
int col = blockIdx.x * TILE_WIDTH + threadIdx.x;
float c_output = 0;
for (int m = 0; m < N/TILE_WIDTH; ++m) {
// 每个线程从全局内存加载 A 的一个元素和 B 的一个元素到共享内存
As[threadIdx.y][threadIdx.x] = A[row * N + (m * TILE_WIDTH + threadIdx.x)];
Bs[threadIdx.y][threadIdx.x] = B[(m * TILE_WIDTH + threadIdx.y) * N + col];
// 我们等待 16x16 块中的所有线程完成加载到共享内存
// 这样它就包含两个 16x16 的块
__syncthreads();
// 然后我们遍历内部维度,
// 每次从全局内存加载一对数据时执行 16 次乘法和 16 次加法
for (int k = 0; k < TILE_WIDTH; ++k) {
c_output += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
// 在所有线程开始将下一个块加载到共享内存之前,
// 等待所有线程完成计算
__syncthreads();
}
C[row * N + col] = c_output;
}
对于外部循环的每次迭代(加载两个元素),线程运行内部循环的 16 次迭代(执行一次乘法和一次加法),相当于每次全局内存读取执行 16 次 FLOP。
这仍然远非完全优化的矩阵乘法内核。Anthropic 的 Si Boehm 的这篇工作日志 详细介绍了进一步增加 FLOP 与内存读取比率并将算法更紧密地映射到硬件上的优化。我们的内核类似于他的内核 1 和内核 3;该工作日志涵盖了十个内核。
该工作日志和本文仅考虑为在 CUDA 核心 上执行而编写内核。绝对最快的矩阵乘法内核反而在 张量核心 上运行,后者具有更高的 算术带宽。