title: 什么是 CUDA 编程模型?
CUDA 代表 Compute Unified Device Architecture(计算统一设备架构)。根据上下文, "CUDA" 可以指代多个不同的事物:一个 高层设备架构, 用于该设计架构的并行编程模型,或是一个 软件平台, 它扩展了像 C 这样的高级语言以添加该编程模型。
CUDA 的愿景在 Lindholm 等人,2008 年 白皮书中进行了阐述。我们强烈推荐这篇论文,它是英伟达文档中许多主张、图表甚至特定措辞的原始来源。
在这里,我们重点介绍 CUDA 编程模型。
计算统一设备架构 (CUDA) 编程模型是一种用于大规模并行处理器的编程模型。
根据 英伟达 CUDA C++ 编程指南, CUDA 编程模型中有三个关键抽象:
- 线程组层次结构。 程序在线程中执行,但可以引用嵌套层次结构中的线程组,从 线程块 到 网格。
- 存储器层次结构。 层次结构每一级的线程组都可以访问一个存储器资源,用于组内通信。访问 存储器层次结构的 最底层 应该 几乎与执行指令一样快。
- 屏障同步。 线程组可以通过屏障来协调执行。
执行和存储器的层次结构及其到 设备硬件 的映射总结在下图中。
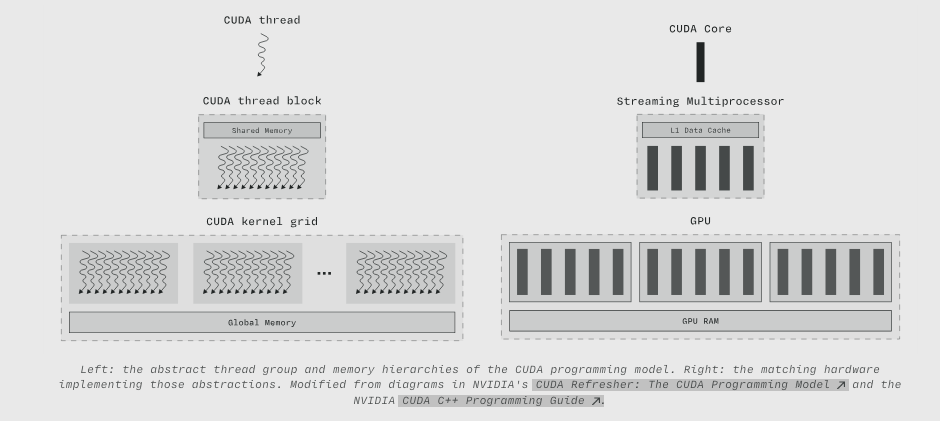
左图:CUDA 编程模型的抽象线程组和存储器层次结构。右图:实现这些抽象概念的匹配硬件。修改自英伟达的 CUDA Refresher: The CUDA Programming Model 和英伟达 CUDA C++ Programming Guide 中的图表。
这三个抽象概念共同鼓励以一种能够随着 GPU 设备并行执行资源的扩展而透明扩展的方式来表达程序。
说得更直接一些:这种编程模型可以防止程序员为英伟达的 CUDA 架构 GPU 编写那些在程序用户购买新的英伟达 GPU 时无法获得加速的程序。
例如,CUDA 程序中的每个 线程块 都可以紧密协调,但块之间的协调是有限的。这确保了线程块捕获了程序的可并行化组件,并且可以按任何顺序进行调度——用计算机体系结构的术语来说,程序员将这种并行性"暴露"给了编译器和硬件。当程序在拥有更多调度单元(具体来说,是更多的 流式多处理器 (Streaming Multiprocessor)) 的新 GPU 上执行时,更多的这些线程块可以并行执行。
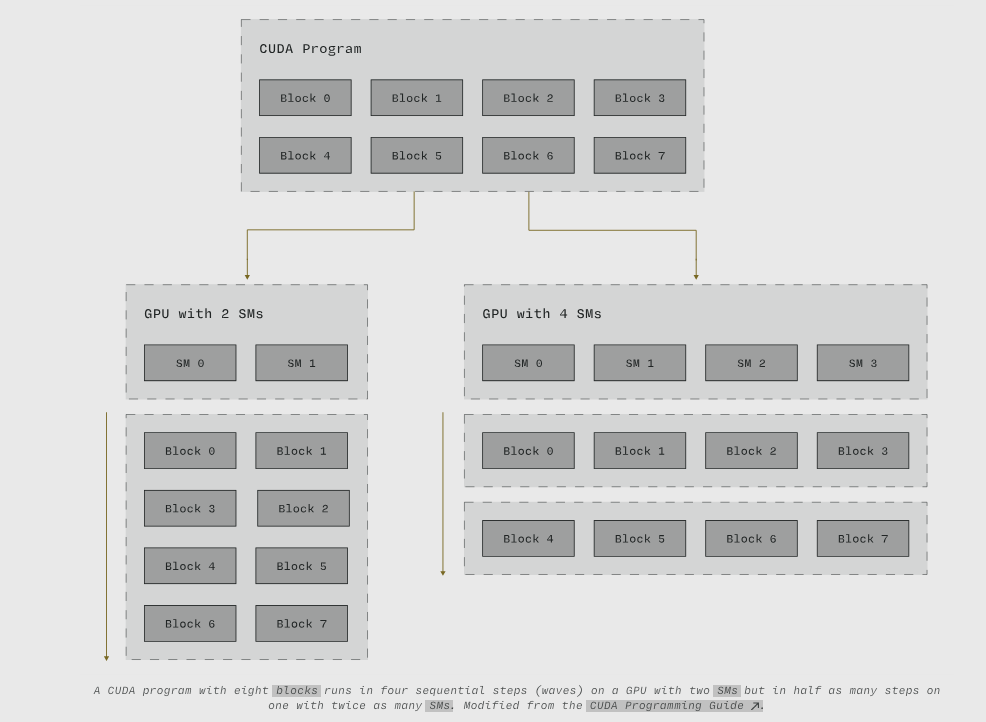
一个包含八个线程块的 CUDA 程序在两个流式多处理器 (SM) 的 GPU 上分四个顺序步骤(波次)运行,但在拥有两倍数量 SM 的 GPU 上,步骤数减少一半。修改自 [CUDA 编程指南](https://docs.nvidia.com/cuda/cuda-c-programming-guide/
CUDA 编程模型的抽象概念通过扩展高级 CPU 编程语言(例如 C++ 的 CUDA C++ 扩展)提供给程序员。该编程模型在软件层面通过指令集架构 (并行线程执行,即 PTX) 和低级汇编语言 (流式汇编器,即 SASS) 来实现。例如,线程层次结构 中的 线程块 级别就是通过这些语言中的 协作线程阵列 (cooperative thread array) 来实现的。