title: 计算受限的含义是什么?
计算受限的内核 (Kernel)受限于CUDA 核心 (CUDA Core)或张量核心 (Tensor Core)的算术带宽 (arithmetic bandwidth)。
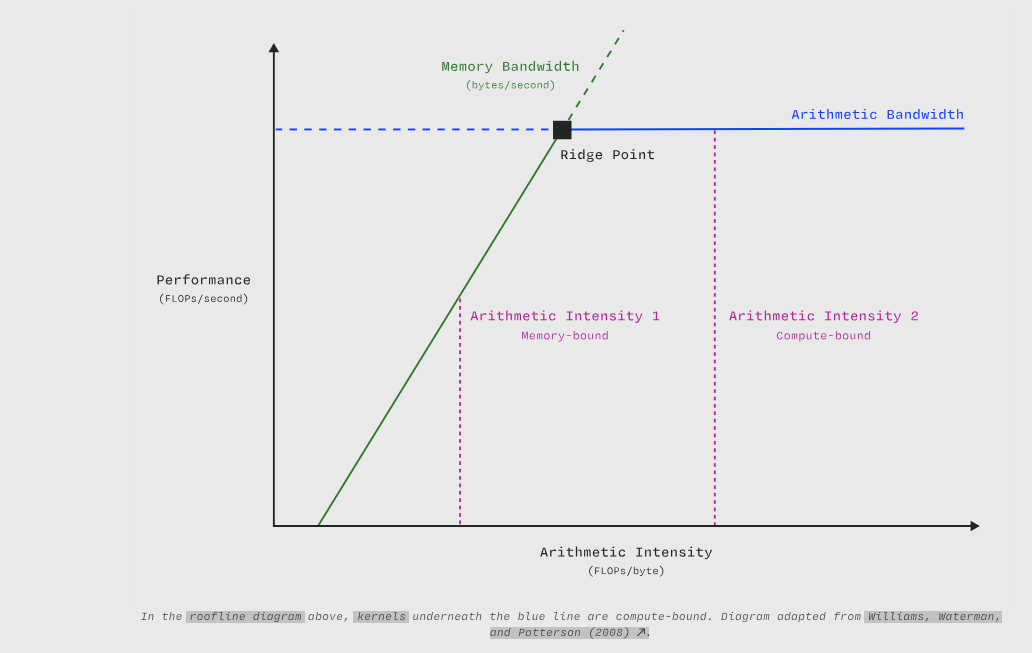
在上方的屋顶线图 (roofline diagram)中,位于蓝线以下的内核 (kernel)属于计算受限。图表改编自Williams, Waterman, and Patterson (2008)。
计算受限内核的特点是具有高算术强度 (arithmetic intensity)(每加载或存储一字节内存需要执行大量算术运算)。算术流水线利用率 (Utilization of arithmetic pipes)是计算受限内核的限制因素。
从技术上讲,计算受限性仅针对单个内核 (kernel)定义,作为屋顶线模型 (roofline model)的一部分,但稍作引申后,可以将其推广到构成典型工作负载的多个内核 (kernel)。
大型扩散模型推理工作负载通常是计算受限的。当代大语言模型推理工作负载在批次预填充/提示处理阶段(当每个权重可以加载到共享内存 (shared memory)中一次,然后跨多个标记重复使用时)通常是计算受限的。
让我们基于kipperrii的Transformer 推理算术框架做一个简单估算,计算计算受限的 Transformer 语言模型推理中标记间的最小延迟(标记间延迟或每个输出标记的时间)。假设模型有 5000 亿参数,以 16 位精度存储,总计 1 TB。该模型每个批次元素将执行约一万亿次浮点运算(每个参数一次乘法和一次累加)。在具有 16 位矩阵运算的 1 petaFLOP/s算术带宽 (arithmetic bandwidth)的 GPU 上运行,假设计算受限,每个批次元素的标记间最小延迟为 1 毫秒。
需要注意的是,要使该 GPU 在批次大小为 1 时达到计算受限,需要具备 1 PB/s 的内存带宽 (memory bandwidth)(以便在 1 毫秒内加载全部 1 TB 权重)。当代内存带宽 (memory bandwidth)在 TB/s 量级,因此需要数百个输入的批次才能提供足够的算术强度 (arithmetic intensity)使执行达到计算受限。
有关 LLM 推理的更多信息,请参阅我们的LLM 工程师指南。